矩陣的特征分解(三步分解,帶您了解特征工程)

入門特征工程:定義、步驟及案例
本文摘自《特征工程入門與實踐》一書,作者是Sinan Ozdemir[土]和Divya Susarla[土],從零入手,幫你全面了解特征工程,提升機器學習算法的效率和準確率。
進階推薦《精通特征工程》,作者是Alice Zheng[美]和Amanda Casari[美],通過Python示例掌握特征工程基本原則和實際應用,增強機器學習算法效果。
以下回答將從定義、步驟和案例三個部分解讀特征工程。廢話不多說,快上車!
一、特征工程的定義
特征工程(feature engineering)是指從原始數據中提取特征并將其轉換為適合機器學習模型的格式。
為了提取知識和做出預測,機器學習使用數學模型來擬合數據。這些模型將特征作為輸入。
特征就是原始數據某個方面的數值表示。在機器學習流程中,特征是數據和模型之間的紐帶。
特征工程是數據科學和機器學習流水線上的重要一環,因為正確的特征可以減輕構建模型的難度,從而使機器學習流程輸出更高質量的結果。
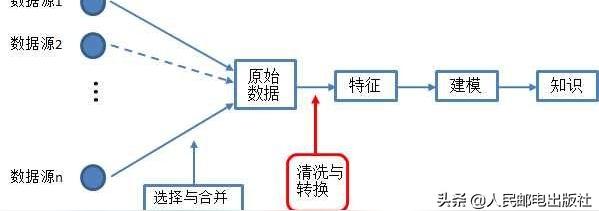
特征工程在機器學習流程中的位置
二、特征工程的5個步驟
經典特征工程包括探索性數據分析、特征理解、特征增強、特征構建和特征選擇5個步驟,為進一步解釋數據并進行預測性分析做準備。
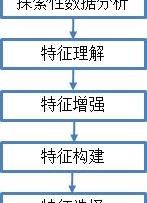
經典特征工程流程
1. 探索性數據分析
探索性數據分析(EDA,exploratory data analysis)
在應用機器學習流水線,甚至在使用機器學習算法或特征工程工具之前,我們應該對數據集進行一些基本的描述性統計(大小、形狀),并進行可視化操作,以便更好地理解數據的性質。
2. 特征理解——識別數據
是指在數據集中識別并提取不同等級的數據,并用這些信息創造有用、有意義的可視化圖表,幫助我們進一步理解數據。
當拿到一個新的數據集時,基本工作流程如下:
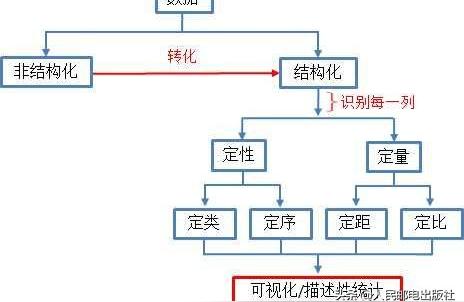
識別數據基本工作流程
a. 數據是結構化 OR 非結構化?
結構化(有組織)數據:可以分成觀察值和特征的數據,一般以表格的形式組織(行是觀察值,列是特征)。例如科學儀器報告的氣象數據是高度結構化的,因為存在表格的行列結構。
非結構化(無組織)數據:作為自由流動的實體,不遵循標準組織結構(例如表格)的數據。通常,非結構化數據在我們看來是一團數據,或只有一個特征(列)。例如以原始文本格式存儲的數據,服務器日志和推文等,是非結構化數據。
b. 數據是定量的 OR 定性的
一般情況下,在處理結構化的表格數據時,第一個問題是:數據是定量的,還是定性的?
定量數據本質上是數值,是衡量某樣東西的數量。
定性數據本質上是類別,是描述某樣東西的性質。
c. 每列數據處于哪個等級?
數據可分為定類、定序、定距和定比四個等級,每個等級都有不同的控制和數學操作等級。數據等級決定了可以執行的可視化類型和操作。
定類等級(nominal level):處理定性數據,只按名稱分類,如血型、動物物種和人名。這個等級不能執行任何諸如加法、除法之類的數學操作,但是可以計數,因此可繪制條形圖和餅圖。
定序等級(nominal level):處理定性數據,這個等級的數據可以自然排序,可進行計數,也可引入比較。但是數據屬性仍然屬于類別。因為能夠計算中位數和百分位數,所以可在條形圖和餅圖的基礎上增加莖葉圖和箱線圖。
定距等級(nominal level):處理定量數據,可以對數值進行排序、比較和加減,引入算數平均數和標準差。可用散點圖、直方圖和折線圖表示。
定比等級(nominal level):處理定量數據,存在有意義的絕對零點,可以對數值進行加減乘除運算,例如¥100是¥50的2倍。可用直方圖和箱線圖表示。
d. 對不同的數據等級進行不同的可視化表示。
3. 特征增強——清洗數據
這個階段是關于改變數據值和列的,根據數據的等級填充缺失值,并按需執行虛擬變量轉換和縮放操作。
清洗數據是指調整已有的列和行,增強數據是指在數據集中刪除和添加新的列。
特征增強的意義是,識別有問題的區域,并確定哪種修復方法最有效。
識別數據中的缺失值
分析數據并了解缺失的數據是什么,這樣才可以決定下一步如何處理這些缺失值。
首先進行探索性數據分析來識別缺失的值。可以使用Pandas和NumPy這兩個Python包來存儲數據并進行一些簡單的計算,使用流行的可視化工具觀察數據的分布情況。
處理數據集中的缺失值
處理缺失值最主要的兩個方法是:
- 刪除缺少值的行:通過這種操作會留下具有數據的完整數據點。
- 填充缺失值:填充指的是利用現有知識/數據來確定缺失的數量值并填充的行為。
對于數值數據,最常見的是用此列其余部分的均值填充缺失值。
對于分類數據,也有類似的處理方法,可計算出最常見的類別用于填充,也可構建自定義填充器處理分類數據的填充。
編碼分類變量
任何機器學習算法,無論是線性回歸還是利用歐幾里得距離的KNN算法,需要的輸入特征都必須是數值。將分類數據轉換為數值數據有以下幾種方法。
方法1:定類等級的編碼
定類等級的編碼主要方法是將分類數據轉換為虛擬變量 (dummy variable),用Pandas自動找到分類變量并進行編碼; 或者創建自定義虛擬變量編碼器,在流水線中工作。
虛擬變量的取值是1或0,代表某個類別的有無,代替定性數據。
方法2:定序等級的編碼
在定序等級,由于數據的順序有含義,使用虛擬變量是沒有意義的,為了保持順序,我們使用標簽編碼器。 標簽編碼器是指,順序數據的每個標簽都會有一個相關數值。
有時,如果數值數據是連續的,那么將其轉換為分類變量可能是有意義的。Pandas有一個有用的函數叫作cut,可以將數據分箱(binning),亦稱為分桶(bucketing),意思就是它會創建數據的范圍。
特征縮放/歸一化
特征縮放旨在改變特征的尺度,提高機器學習模型的準確率,也稱為歸一化。
常見的特征縮放操作有z分數標準化、min-max標準化和行歸一化等。
4. 特征構建——生成新特征
使用現有特征構建全新的特征,以便理解特征交互情況。
構建新特征方法
方法1:最簡單的方法是用Pandas將現有的特征擴大幾倍;
用Pandas創建DataFrame,這也是Pandas的主要數據結構。這樣做的優點是可以用很多屬性和方法操作數據,從而對數據進行符合邏輯的操作,以深入了解我們使用的數據,以及如何最好地構建機器學習模型。
方法2:依靠數學的方法,使用scikit-learn包 ,擴展數值特征;
在處理數值數據、創建更多特征時,一個關鍵方法是使用 scikit-learn 的PolynomialFeatures 類。這個構造函數會創建新的列,它們是原有列的乘積,用于捕獲特征交互。 更具體地說,這個類會生成一個新的特征矩陣,里面是原始數據各個特征的多項式組合,階數小于或等于指定的階數。
兩個特征的乘積可以組成一對簡單的交互特征,這種相乘關系可以用邏輯操作符AND來類比,它可以表示出由一對條件形成的結果:“該購買行為來自于郵政編碼為98121的地區”AND“用戶年齡在18~35歲之間”。這種特征在基于決策樹的模型中及其常見,在廣義線性模型中也經常使用。
方法3:編寫自己的類。
針對文本的特征構建方法
在日常生活中,我們很大程度通過書面文本的方式進行溝通,通過建模,我們可以從中獲得海量信息,如商戶點評等。
這個工作又叫做自然語言處理(NLP,natural language processing)。
文本數據稱為語料庫(corpus),尤其是指文本內容或文檔的集合。
文本數據比單個類別的文本復雜得多,因為長文本包括一系列類別,又稱為詞項(token)。
針對文本的特征構建有詞袋法、TF-IDF向量化器等方法。
方法1:詞袋法
將語料庫轉換為數值表示(也就是向量化)的常見方法是詞袋(bag of words)。
詞袋法基本思想:通過單詞的出現來描述文檔,完全忽略單詞在文檔中的位置。在它最簡單的形式中,用一個袋子表示文本,不考慮語法和詞序,并將這個袋子視作一個集合,其中重復度高的單詞更重要。
詞袋法分3個步驟:
- 分詞(tokenizing):分詞過程是用空白和標點將單詞分開,將其變為詞項。每個可能出現的詞項都有一個整數ID。
- 計數(counting):簡單地計算文檔中詞項的出現次數。
- 歸一化(normalizing):將詞項在大多數文檔中的重要性按逆序排列。
方法2:TF-IDF向量化器
TF-IDF是一個用于信息檢索和聚類的詞加權方法。對于語料庫中的文檔,TF-IDF會給出其中單詞的權重,表示重要性。
TF-IDF向量化器由兩部分組成:
- TF(term frequency,詞頻):衡量詞在文檔中出現的頻率。由于文檔的長度不同,詞在長文中的出現次數有可能比在短文中出現的次數多得多。因此,一般會對詞頻進行歸一化,用其除以文檔長度或文檔的總詞數。
- IDF(inverse document frequency,逆文檔頻率):衡量詞的重要性。在計算詞頻時,我們認為所有的詞都同等重要。但是某些詞有可能出現很多次,但這些詞并不重要。因此,我們需要減少常見詞的權重,加大稀有詞的權重。
5. 特征選擇——發掘數據的新特征
在選擇階段,用所有原始和新構建的列(通常是單變量)進行統計測試,選取性能最佳的特征,以消除噪聲影響,加速計算。
特征選擇是從原始數據中選擇對于預測流水線而言最好的特征的過程。即,給定n個特征,我們搜索其中包括k(k<n)個特征的子集來改善機器學習流水線的性能。
粗略地說,特征選擇技術可以分為以下三類:
過濾:
過濾技術對特征進行預處理,以除去那些不太可能對模型有用處的特征。例如,我們可以計算出每個特征與響應變量之間的相關性或互信息,然后過濾掉那些在某個閾值之下的特征。過濾技術的成本比下面描述的打包技術低廉得多,但它們沒有考慮我們要使用的模型,因此,它們有可能無法為模型選擇出正確的特征。使用預過濾技術時需要謹慎,防止不經意地刪除有用特征。
打包方法:
這些技術的成本非常高昂,但是可以試驗特征的各個子集,這意味著我們不會意外地刪除那些本身不提供什么信息但和其他特征組合起來卻非常有用的特征。打包方法將模型視為一個能對推薦的特征子集給出合理評分的黑盒子。它們使用另外一種方法迭代地對特征子集進行優化。
嵌入式方法:
嵌入式方法將特征選擇整合為模型訓練過程的一部分,它不如打包方法強大,但成本也遠不如打包方法那么高。與過濾技術相比,嵌入式方法可以選擇出特別適合某種模型的特征。從這個意義上說,嵌入式方法在計算成本和結果質量之間實現了某種平衡。
選用正確的特征選擇方法,一般建議:
如果特征是分類的,那么從SelectKBest開始,用卡方或基于樹的選擇器。
如果特征基本是定量的,一般用線性模型和基于相關性的選擇器效果更好。
如果二元分類問題,考慮使用SelectFromModel和SVC,因為SVC會查找優化二元分類任務的系數。
在手動選擇前,探索性分析會很有益處,不能低估領域知識的重要性。
以上就是經典特征工程的5個主要步驟,接下來簡單介紹一下轉換數據的方法。
特征轉換——數學顯神通
特征轉換是一組矩陣算法,會在結構上改變數據,產生本質上全新的數據矩陣。
特征轉換方法可以用每個列中的特征創建超級列(super-column),所以不需要創建很多新特征就可以捕獲所有潛在的特征交互。因為特征轉換算法涉及矩陣和線性代數,所以不會創造出比原有列更多的列,而且仍能提取出原始列中的結構。
與特征選擇不同的是,特征選擇僅限于從原始列中選擇特征;特征轉換算法則將原始列組合起來,從而創建可以更好地描述數據的特征。
主成分分析
主成分分析(PCA,principal components analysis)是將有多個相關特征的數據集投影到相關特征較少的坐標系上。這些新的、不相關的特征(超級列)叫主成分。主成分能替代原始特征空間的坐標系,需要的特征少,捕捉的變化多。
換句話說,PCA的目標是識別數據集中的模式和潛在結構,以創建新的特征,而非使用原始特征。和特征選擇類似,如果原始數據是n×d大小(n是觀察值數,d是原始的特征數),那么我們會將這個數據集投影到n×k(k<d)的矩陣上。
一般,PCA分為4個步驟:
創建數據集的協方差矩陣;
計算協方差矩陣的特征值;
降序排列特征值,保留前k個特征值;
用保留的特征向量轉換新的數據點。
線性判別分析
線性判別分析(LDA,liear discriminant analysis)是特征變換算法,一般用作分類流水線的預處理步驟。和PCA一樣,LDA的目標是提取一個新的坐標系,將原始數據集投影到一個低維空間中。
LDA和PCA的主要區別在于,LDA不會專注于數據的方差,而是優化低維空間,已獲得最佳的類別可分性。
LDA分為5個步驟:
計算每個類別的均值向量;
計算類內和類間的散布矩陣;
計算 特征值和特征向量;
降序排列特征值,保留前k個特征向量;
使用前幾個特征向量將數據投影到新空間。
三、案例:面部識別
這個案例研究的是scikit-learn中Wild數據集里的面部數據集。這個數據集叫作JAFFE,包括一些面部照片以及適當的表情標簽。我們的任務是面部識別,即進行有監督的機器學習,預測圖像中人物的表情。
1. 數據
首先加載數據集,導入用于繪制數據的包。在Jupyter Notebook的最上方盡量放置所有導入語句。
# 特征提取模塊from sklearn.decomposition import PCAfrom sklearn.discriminant_analysis import LinearDiscriminantAnalysis# 特征縮放模塊from sklearn.preprocessing import StandardScaler# 標準Python模塊from time import timeimport numpy as npimport matplotlib.pyplot as plt# scikit-learn 的特征選擇模塊from sklearn.model_selection import train_test_split, GridSearchCV, cross_val_score#指標from sklearn.metrics import classification_report, confusion_matrix, accuracy_score# 機器學習模塊from sklearn.linear_model import LogisticRegressionfrom sklearn.pipeline import Pipeline然后可以開始了!步驟如下所示。
(1) 首先加載數據集:
import osdata_path='F:\python\locust\.idea\dictionaries\jaffe'data_dir_list=os.listdir(data_path)img_rows=256img_cols=256num_channel=1num_epoch=10img_data_list=[]import cv2for dataset in data_dir_list: img_list=os.listdir(data_path+'/'+dataset) print('Loaded the images of dataset-'+'{}\n'.format(dataset)) for img in img_list: input_img=cv2.imread(data_path+'/'+dataset+'/'+img) input_img=cv2.cvtColor(input_img,cv2.COLOR_BGR2GRAY) input_img_resize=cv2.resize(input_img,(128,128)) img_data_list.append(input_img_resize)img_data=np.array(img_data_list)img_data=img_data.astype('float32')img_data=img_data/255img_data.s(2) 檢查圖像數組,輸出圖像大小:
n_samples,h,w=img_data.shapen_samples,h,w(213,128,128)
一共有213個樣本(圖像),高度和寬度都是128像素。
(3) 接著設置流水線的x和y變量:
#直接使用 不管相對像素位置X=img_datalabels = ['angry','disgust','fear','happy','','','']Y=labelsn_features=X.shape[1]n_features
16384
n_features的數量是16384,因為:
128*128=16384
輸出數據的形狀
X.shape
(213,16384)
2. 數據探索
數據有213行和16384列。我們可以繪制一幅圖像,進行探索性數據分析。
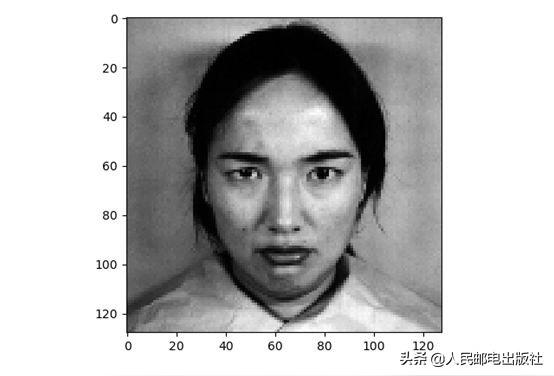
#繪制其中一張臉
plt.imshow(X[6].reshape((h,w)), cmap=plt.cm.gray)print(Y[0])plt.show()給出的標簽是:
'angry'
該圖像如下所示。
我們在縮放后重新繪制一次圖像:
#縮放后重新繪制一次圖像print(X.shape)img = StandardScaler().fit_transform(X[6]).reshape((h,w))plt.imshow(img)plt.show()print(Y[0])輸出:
'angry'
得到的圖像如下所示。
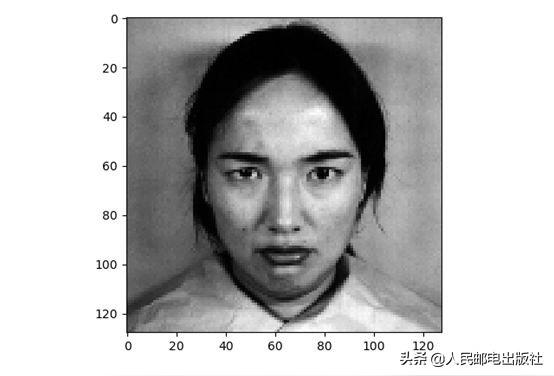
可以看見,圖像略有不同,臉部周圍的像素變暗了。現在設置預測的標簽:
#預測表情
target_names=labels_textn_samples=X.shape[0]n_classes=len(names)print("Total dataset size:")print("n_samples: %d" % n_samples)print("n_features: %d" % n_features)print("n_classes: %d" % n_classes)輸出是:
Total dataset size:n_samples: 213n_features: 16384n_classes:73. 應用面部識別
現在可以開始構建機器學習流水線來創建面部識別模型了。
(1) 首先創建訓練集和測試集,對數據進行分割:
# 把數據分成訓練集和測試集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25,random_state=1)(2) 現在可以在數據集上進行主成分分析(PCA)了:
先將PCA 實例化,在進入流水線之前進行數據擴充。方法如下:
# PCA 實例化pca = PCA(n_components=50, whiten=True)# 創建流水線,擴充數據,然后應用PCApreprocessing = Pipeline([('scale', StandardScaler()), ('pca', pca)])(3) 現在擬合流水線:
print("Extracting the top %d eigenfaces from %d faces" % (50, X_train.shape[0]))# 在訓練集上擬合流水線preprocessing.fit(X_train)# 從流水線上取PCAextracted_pca = preprocessing.steps[1][1](4) print 語句的輸出是:
Extracting the top 50 eigenfaces from 159 faces(5) 看一下碎石圖:
# 碎石圖plt.plot(np.cumsum(extracted_pca.explained_variance_ratio_))得到的圖像如下圖所示。
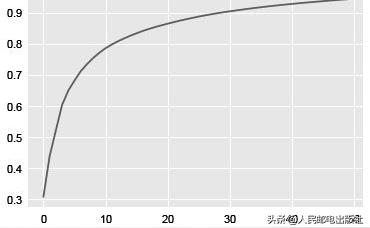
可以看出,30 個主成分就可以表示90%以上的方差,和原始的特征數量相比很可觀。
(6) 可以創建函數,繪制PCA 的主成分:
comp = extracted_pca.components_image_shape = (h, w)def plot_gallery(title, images, n_col, n_row):plt.figure(figsize=(2. * n_col, 2.26 * n_row))plt.suptitle(title, size=16)for i, comp in enumerate(images):plt.subplot(n_row, n_col, i + 1)vmax = max(comp.max(), -comp.min())plt.imshow(comp.reshape(image_shape), cmap=plt.cm.gray,vmin=-vmax, vmax=vmax)plt.xticks(())plt.yticks(())plt.subplots_adjust(0.01, 0.05, 0.99, 0.93, 0.04, 0.)plt.show()(7) 現在可以調用plot_gallery 函數:
plot_gallery('PCA componenets', comp[:16], 4,4)輸出如下圖所示。

可以看見每行每列的PCA 主成分了!這些特征臉(eigenface)是PCA 模塊發現的人臉特征。
每個主成分都包括了可以區分不同人臉的重要信息,例如:
第四行第一列的特征臉好像突出了腮部表情;
第二行第三列的特征臉好像顯示了嘴部的變化。
當然,不同的面部數據集會輸出不同的特征臉。接下來創建的函數可以更清晰地顯示混淆矩陣,包括熱標簽和歸一化選項:
import itertoolsdef plot_confusion_matrix(cm, classes,normalize=False,title='Confusion matrix',cmap=plt.cm.Blues):plt.imshow(cm, interpolation='nearest', cmap=cmap)plt.title(title)plt.colorbar()tick_marks = np.arange(len(classes))plt.xticks(tick_marks, classes, rotation=45)plt.yticks(tick_marks, classes)thresh = cm.max() / 2.for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):plt.text(j, i, cm[i, j],horizontalalignment="center",color="white" if cm[i, j] > thresh else "black")plt.ylabel('True label')plt.xlabel('Predicted label')現在不使用PCA 也可以看見差異。我們查看一下模型的準確率:
# 不用PCA,看看差異t0 = time()logreg = LogisticRegression()param_grid = {'C': [1e-2, 1e-1, 1e0, 1e1, 1e2]}clf = GridSearchCV(logreg, param_grid)clf = clf.fit(X_train, y_train)best_clf = clf.best_estimator_# 用測試集進行預測y_pred = best_clf.predict(X_test)print(accuracy_score(y_pred, y_test), "Accuracy score for best estimator")print(plot_confusion_matrix(confusion_matrix(y_test, y_pred,labels=range(n_classes)), target_names))print(round((time() - t0), 1), "seconds to grid search and predict the test set")輸出如下:
0.7592592592592593 Accuracy score for best estimator309.5 seconds to grid search and predict the test set在只使用原始像素的情況下,我們的線性模型可以達到75.9%的準確率。下面看看應用PCA
后會不會有所不同,把主成分數量設置成200:
# 用PCAt0 = time()face_pipeline = Pipeline(steps=[('PCA', PCA(n_components=200)), ('logistic',logreg)])pipe_param_grid = {'logistic__C': [1e-2, 1e-1, 1e0, 1e1, 1e2]}clf = GridSearchCV(face_pipeline, pipe_param_grid)clf = clf.fit(X_train, y_train)best_clf = clf.best_estimator_# 用測試集進行預測y_pred = best_clf.predict(X_test)print(accuracy_score(y_pred, y_test), "Accuracy score for best estimator")print(classification_report(y_test, y_pred, target_names=target_names))print(plot_confusion_matrix(confusion_matrix(y_test, y_pred,labels=range(n_classes)), target_names))print(round((time() - t0), 1), "seconds to grid search and predict the test set")應用PCA 后的輸出如下:
0.6666666666666666 Accuracy score for best estimator4.9 seconds to grid search and predict the test set有意思!可以看到,準確率下降到了66.7%。
現在做一個網格搜索,尋找最佳模型和準確率。首先創建一個執行網格搜索的函數,它會輸
出準確率、參數、平均擬合時間和平均分類時間。函數的創建方法如下:
def get_best_model_and_accuracy(model, params, X, y):grid = GridSearchCV(model, # 網格搜索的模型params, # 搜索的參數error_score=0.) # 如果出錯,正確率是0grid.fit(X, y) # 擬合模型和參數# 經典的性能參數print("Best Accuracy: {}".format(grid.best_score_))# 得到最佳準確率的最佳參數print("Best Parameters: {}".format(grid.best_params_))# 擬合的平均時間(秒)print("Average Time to Fit (s):{}".format(round(grid.cv_results_['mean_fit_time'].mean(), 3)))# 預測的平均時間(秒)# 從該指標可以看出模型在真實世界的性能print("Average Time to Score (s):{}".format(round(grid.cv_results_['mean_score_time'].mean(), 3)))現在可以創建一個更大的網格搜索流水線,包含更多的組件:
縮放模塊;
PCA 模塊,提取捕獲方差的最佳特征;
線性判別分析(LDA)模塊,創建區分人臉效果最好的特征;
線性分類器,利用上述3 個特征工程模塊的結果,嘗試對人臉進行區分。
創建大型流水線的代碼如下:
# 網格搜索的大型流水線face_params = {'logistic__C':[1e-2, 1e-1, 1e0, 1e1, 1e2],'preprocessing__pca__n_components':[100, 150, 200, 250, 300],'preprocessing__pca__whiten':[True, False],'preprocessing__lda__n_components':range(1, 7)# [1, 2, 3, 4, 5, 6] recall the max allowed is n_classes-1}pca = PCA()lda = LinearDiscriminantAnalysis()preprocessing = Pipeline([('scale', StandardScaler()), ('pca', pca), ('lda', lda)])logreg = LogisticRegression()face_pipeline = Pipeline(steps=[('preprocessing', preprocessing), ('logistic',logreg)])get_best_model_and_accuracy(face_pipeline, face_params, X, y)結果如下:
Best Accuracy: 0.8276995305164319Best Parameters: {'logistic__C': 10.0, 'preprocessing__lda__n_components': 6,'preprocessing__pca__n_components': 100, 'preprocessing__pca__whiten': True}Average Time to Fit (s): 0.213Average Time to Score (s): 0.007可以看見,準確率大幅度提高,預測的速度極快!
有很多方法可以增強機器學習的效果,通常我們認為最主要的兩個特征是準確率和預測/擬合時間。如果利用特征工程工具后,機器學習的流水線的準確率在交叉驗證中有所提高,或者擬合/預測的速度加快,那就代表特征工程成功了。
當然如果既優化準確率又優化時間,構建出更好的流水線那就更好了。
以上內容整理自《特征工程入門與實踐》一書,作者:Sinan Ozdemir[土],Divya Susarla[土]。

[土] Sinan Ozdemir [土]Divya Susarla 著 莊嘉盛 譯
本書帶你從零入手,全面了解特征工程,從而提升機器學習算法的效率和準確率。學習本書:
你會了解特征工程的完整過程,使機器學習更加系統、高效。
你會從理解數據開始學習,機器學習模型的成功正是取決于如何利用不同類型的特征,例如連續特征、分類特征等。
你將了解何時納入一項特征、何時忽略一項特征以及其中的原因。
你還會學習如何將問題陳述轉換為有用的新特征,如何提供由商業需求和數學見解驅動的特征,以及如何在自己的機器上進行機器學習,從而自動學習數據中的特征。
最重要的是,本書在講解的同時會增加很多實例,幫助理解。
相關閱讀:《精通特征工程》,作者:Alice Zheng[美],Amanda Casari[美]。

[美]Alice Zheng [美]Amanda Casari 著 陳光欣 譯
本書介紹了大量的特征工程技術,闡明特征工程的基本原則。主要內容包括:機器學習流程中的基本概念,數值型數據的基礎特征工程,自然文本的特征工程,詞頻-逆文檔頻率,高效的分類變量編碼技術,主成分分析,模型堆疊,圖像處理等。