以太坊 2.0(以太坊2.0共識客戶端的分析)
信息來源自Medium,略有修改,作者Migalabs
以太坊正在進行重大升級,旨在使網絡更可持續,從工作證明(PoW)過渡到股權證明,并隨著數據分片的引入提高可擴展性。這一過程從2020年12月部署Beacon Chain開始,下一步稱為Merge,預計將在今年晚些時候進行。在本文中,我們將探討以太坊2.0生態系統在這次轉型中取得了多大的進展,以及為進入下一階段做了哪些準備。
為此目的,我們對在不同硬件、多個設置配置和幾個用例下的以太坊2.0共識層(CL)客戶端進行了全面的研究。這項研究花費了幾個月的時間,消耗了近30000個CPU小時(3.4個CPU年),在此期間我們收集了超過7.35億個數據點,從中提取了近1.5億個數據點,繪制了大約1000個不同的數據,以顯示不同的CL客戶端的表現。
實驗設置
我們測量了CL客戶端在三個不同的硬件平臺上的表現,一個標準節點、一個胖節點和一個Raspberry Pi 4b。各類型節點的硬件配置如表1所示。

? 表1 硬件規格
我們還測試了默認配置以及所有主題配置以及客戶端偵聽 GossipSub 層上的所有子主題的全主題配置。我們測試的客戶端和版本如下:
Prysm: 2.0.6
Lighthouse: 2.1.4
Teku: 22.3.2
Nimbus: 1.6.0
Lodestar: 0.34.0
Grandine: 0.2.0
整體性能分析
在下文中,我們將討論我們的一些發現。我們收集了如此多的數據,根本不可能在這篇文章中討論所有的細節。然而,我們將試著回顧一些最重要的問題。首先,我們繪制了不同CL客戶端的CPU使用情況(圖1)和內存消耗情況(圖2)。我們看到,大多數CL客戶端在標準節點上對CPU的使用都很合理。
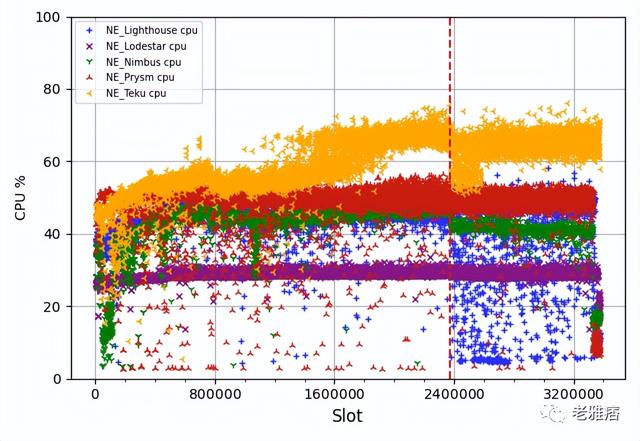
? 圖1 CPU消耗
就內存而言,它們都表現出了不同的性能。在這個實驗中,Nimbus是內存消耗最低的一個。Lighthouse的內存消耗持續增加,直到客戶端崩潰,我們不得不重新啟動它。這可能是某種類型的內存泄漏,我們的團隊與Lighthouse團隊討論過這個問題,他們正在調查這個問題。在為Teku的Java虛擬機(JVM)設置內存時,我們也遇到了一些問題,這也解釋了在運行初期出現的奇怪模式。請注意,在某個時刻,大多數客戶端在CPU使用和內存消耗方面開始表現不同,這一點在CPU圖中用紅色虛線表示。這條線標志著向Altair硬分叉的過渡。從Altair開始,CL客戶端需要跟蹤同步單元,以及削減條件的其他重大變化,這解釋了資源消耗的變化。
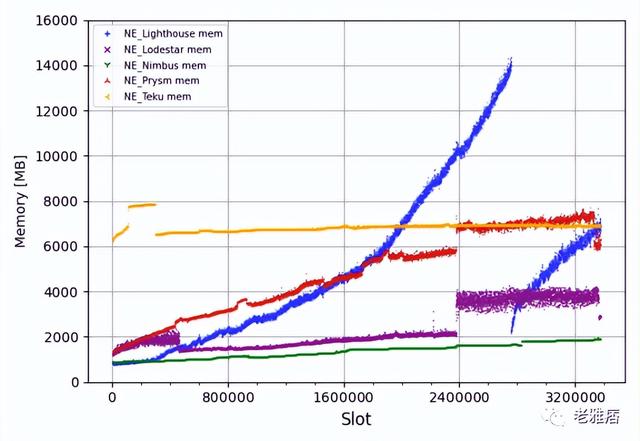
? 圖2 內存消耗
如果我們看一下磁盤使用情況(圖3),我們會注意到不同客戶端需要的存儲空間有很大的不同,例如Lighthouse占用的存儲空間是Teku的三倍,Teku是CL客戶端中占用存儲空間最少的,其次是Nimbus。
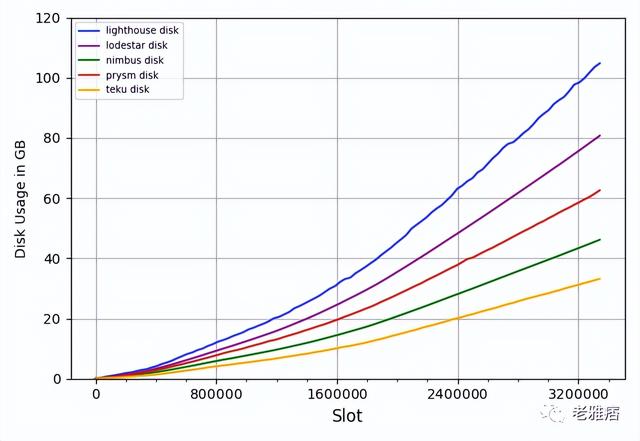
? 圖3 磁盤使用情況
在磁盤寫入操作方面(圖4),大多數客戶端,尤其是Prysm,在同步過程開始時,每秒的磁盤寫入操作次數較多,這一數字逐漸減少,直到Altair之后趨于平穩。
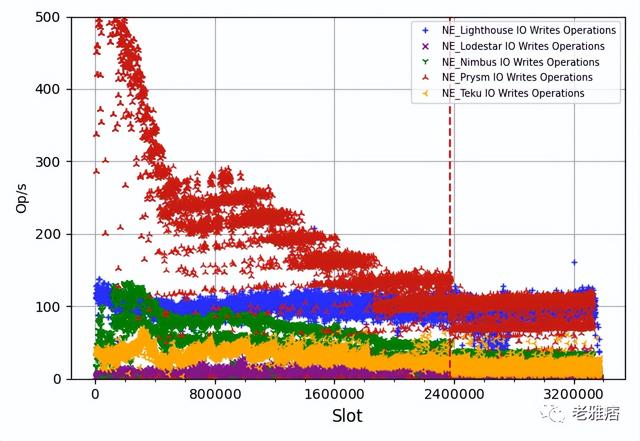
? 圖4 每秒的磁盤寫入操作
這可以解釋為,在Beacon鏈的初期,驗證者的數量遠低于今天,而這些時段的時隙處理速度要快得多。這兩個數字是相關的,正如我們在圖3中所看到的,隨著網絡中驗證者和證明數量的增加,磁盤使用量的增長在前半段相當低,在后半段則加速。
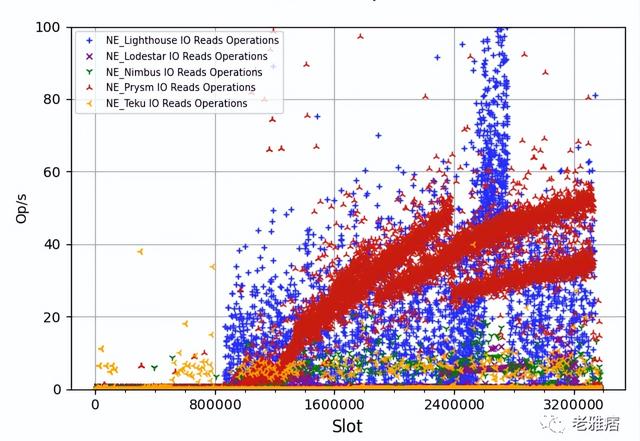
? 圖5 每秒磁盤讀取操作次數(標準節點)
關于每秒磁盤讀取操作,我們發現了一個模式,我們已經與不同的團隊討論過,但還沒有完全理解這種模式。在某個時刻,磁盤讀取操作會急劇增加,這在除了Teku的大多數CL客戶端中都可以觀察到。這并不是一個真正的問題,因為它不會影響性能,但我們仍在試圖理解為什么會發生這種情況。最明顯暴露出這種行為的客戶端是Prysm。我們已經與Prysmatic團隊分享了這一發現,他們正在調查這一模式。更奇怪的是,對于大多數客戶端來說,這幾乎上是同時發生的,如圖5所示,大約在slot 900K。
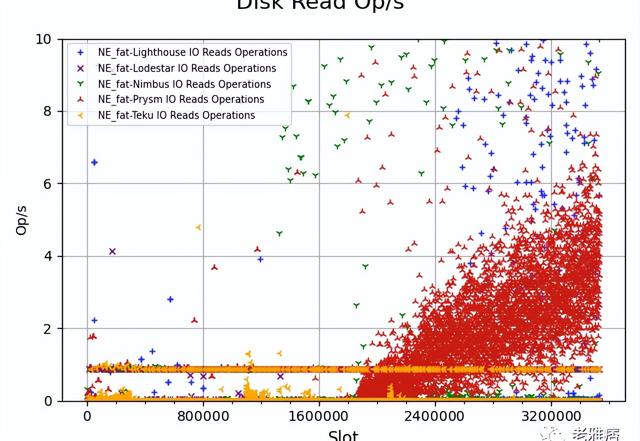
? 圖6 每秒磁盤讀取操作(胖節點)
我們在胖節點上重復了這個實驗,我們看到了幾乎相同的情況(圖6),但這次的模式開始得要晚得多,大約在slot 2M附近。我們注意到這種情況也發生在Raspberry Pi上,但要更早。事實上,在擁有更多內存的節點上,這種現象發生得更晚,這使我們相信有某種內存緩存進程正在進行。當客戶端達到其緩沖限制時,它開始產生大量的磁盤讀取。
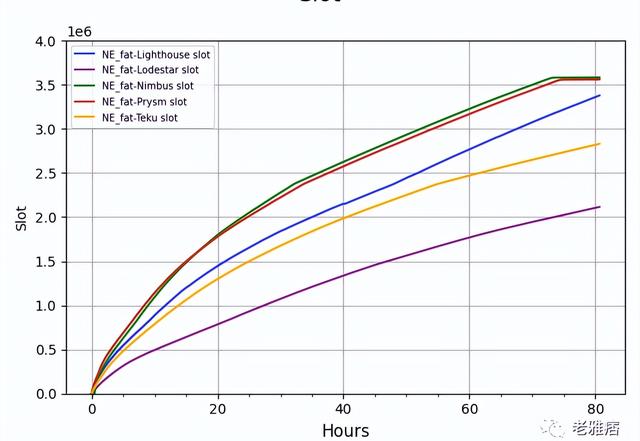
? 圖7 從genesis的同步時間
在我們所做的大多數實驗中,我們必須要同步CL客戶端。我們同時嘗試了兩種方法,即從genesis同步和從檢查點同步。這是一個有爭議的觀點,因為許多人表示,從genesis測量的同步速度不應該相關,還有人說,不管主觀性多弱,從genesis開始同步仍然是該領域最常見的做法。由于我們對兩者都進行了測試,所以我們給出了結果。在圖7中,我們展示了CL客戶端的同步速度。我們可以看到,Nimbus是所有開源CL客戶端中同步速度最快的客戶端。
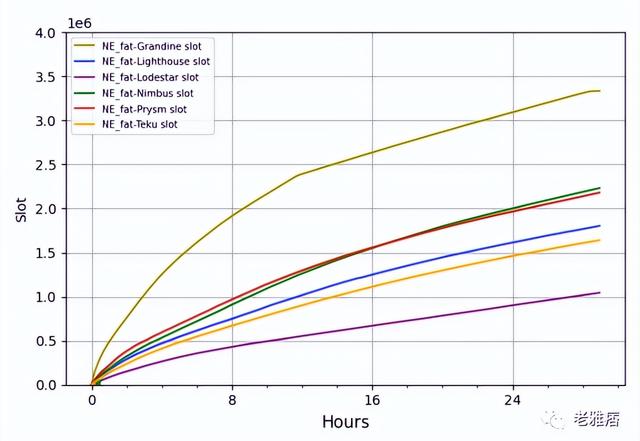
? 圖8 胖節點上的同步速度
我們還測試了Grandine,這是一個封閉源代碼的CL客戶端,它似乎在并行化共識處理的某些方面投入了大量的精力。在Grandine的高速處理中可以觀察到這一點,如圖8所示,這使得它的同步速度比所有其他客戶端都快。請注意與磁盤寫入操作類似的模式(圖4)。實際上,slot的處理速度在開始時要快得多,然后迅速下降,直到達到平穩狀態,這也與Beacon鏈開始時網絡中驗證者的數量較少有關。
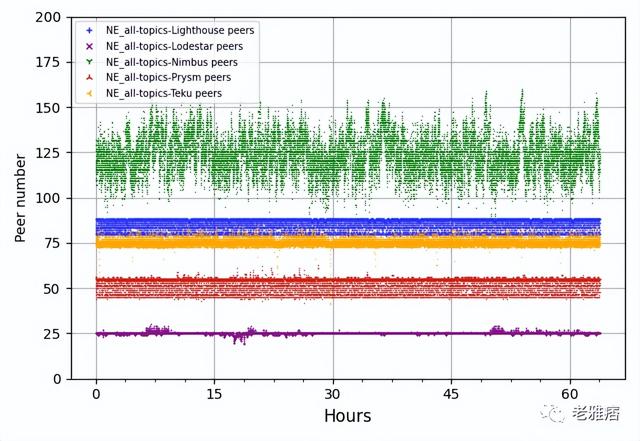
?圖9 對等體數量
在網絡帶寬利用率方面,我們分析了CL客戶端配對的對等體數量,我們可以看到有顯著的差異(圖9)。Lodestar只與25個對等體配對,而Nimbus是最靈活的,其范圍在100到150個對等體之間,平均約125個對等體。Prysm顯示的范圍在40和60個對等體之間搖擺不定。Lighthouse和Teku也顯示出非常穩定的對等策略。值得一提的是,我們對所有客戶端的對等限制使用了默認配置。我們之所以選擇這樣做,是因為CL客戶團隊解釋說,他們的客戶端對這些數字進行了“優化”,更改它可能會影響性能。
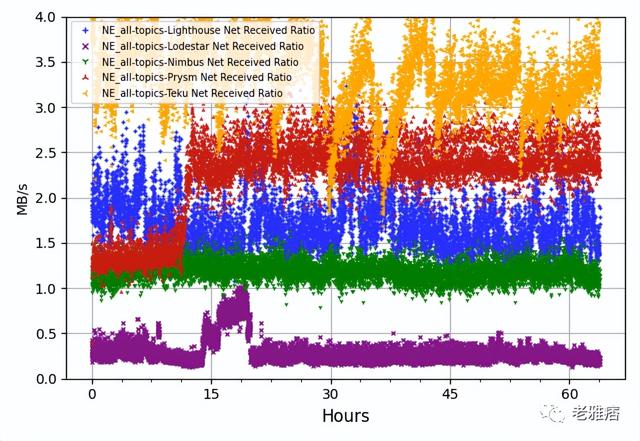
? 圖10 網絡發送數據(MB/s)
當我們將其與網絡活動進行比較時(圖10),結果與預期略有不同。Nimbus擁有最多的對等體,但比大多數其他客戶端占用更少的帶寬。Lodestar帶寬消耗低,這與對等體數量最少的情況相符。相反,Teku占用比所有客戶端更多的帶寬,當啟用all-topics選項時,這一點尤其明顯。我們已經與Teku團隊分享了這些發現,他們正在調查這種高網絡活動。Teku團隊報告稱,自v22.5.1更新以來,CPU減少了25%,輸出帶寬減少了38%。Lodestar在所有主題上也顯示出一些奇怪的模式,在這種模式下,它發送的數據比默認模式下要少。Lodestar團隊正在調查這個問題。
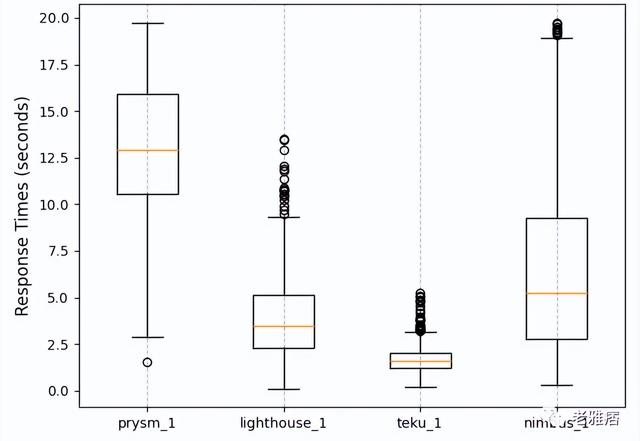
? 圖11 API響應時間
我們還研究了CL客戶端在存檔模式下的行為(只有四個客戶端支持存檔模式)。存檔模式是一種配置,在這種配置中,客戶端存儲了許多中間狀態,以便能夠輕松地回答關于區塊鏈歷史上任何時間的查詢。這在設置區塊資源管理器或一些類似的API時特別有用。我們向四個CL客戶端發送了數千個請求,并記錄了它們的響應時間,如圖11所示。在這方面最慢的客戶端是Prysm,因為他們只支持部分標準API,所以他們將查詢轉換為gRPC上的另一個接口,這增加了一定的開銷。到目前為止,在存檔模式下回答查詢的所有客戶端中,速度最快的是Teku,其響應時間非常快且穩定。在與Teku團隊的交談中,他們向我們解釋說,他們開發了一種新的極其快速的樹狀結構狀態存儲來快速回答查詢,這對Infura團隊來說尤其有趣。
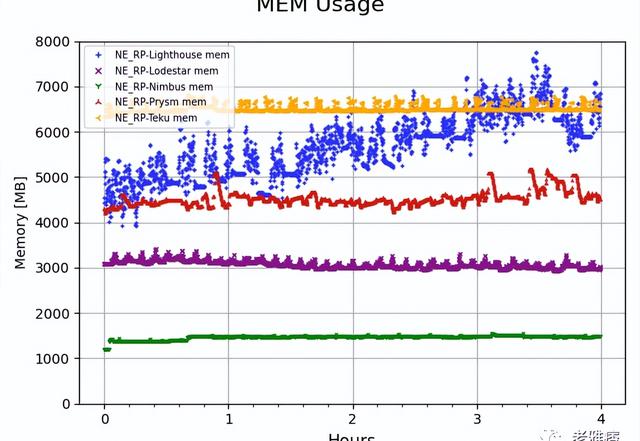
? 圖12 Raspberry Pi上的內存使用情況
最后,我們在Raspberry Pi設備上測試了客戶端。在這么小的設備上從genesis同步可能需要很長時間。令人高興的是,檢查點同步工作正常,所有CL客戶端在這些低功耗設備上都表現得相當好。圖12顯示了Raspberry Pi上CL客戶端的內存使用情況。
優點和改進點
在這個詳盡的評估過程中,我們發現了所有以太坊CL客戶端的多個優點和改進空間。我們本研究的目標有三個方面:i)為CL客戶端團隊提供有用的反饋;ii)向以太坊基金會提供大量數據,以衡量以太坊2.0 CL客戶端的準備情況;iii)最后但并非最不重要的是,為權益池運營商提供他們所需的所有信息,以指導有關CL客戶端部署的決策。
上述評估給出了關于以太坊CL客戶端在不同場景下表現的經驗數據。然而,當在操作平臺上部署軟件時,還有許多其他方面也發揮著重要作用。請注意,其中一些方面可能是主觀的,其他人可能不同意我們的結論。在接下來的內容中,我們試圖涵蓋其中的一些方面,并結合實測的經驗數據,討論以太坊CL客戶端的優勢和改進點。
Prysm
對于我們的團隊來說,Prysm顯然是擁有最佳用戶體驗的客戶端。它非常易于使用并部署在默認配置上。Prysmatic團隊在改善用戶體驗方面付出了巨大的努力。另一方面,Prysm在幾個方面還有優化的空間。文檔門戶有待改進,搜索功能不是很直觀。此外,它們使用gRPC,標準的HTTP API被重定向到gRPC,這顯示出了低性能,甚至在同時執行多個請求時出現了崩潰。存檔模式下的同步比其他客戶端花費了更多時間。
Lighthouse
這是具有最完整API的客戶端。它幾乎實現了所有的Eth2 Beacon節點的API標準,這就是為什么我們用它來檢查CL客戶端獎勵和其他相關數據。另一方面,該客戶端在從Genesis同步時似乎有一些內存泄漏,而且它的存儲消耗是所有客戶端中最高的。應該檢查內存和IO管理。
Teku
Teku似乎是最穩定的客戶端之一,它具有非常完整的文檔,在其中可以很容易地找到任何執行選項和命令行標志。此外,它是存儲需求最低的客戶端,存檔模式在所有客戶端中具有最快的API響應時間。然而,盡管響應時間很快,但在存檔模式下同步需要很長時間(超過3周)。另外,正確設置JVM以避免內存問題并不總是那么容易。
Nimbus
Nimbus是所有平臺上CPU和內存需求最低的客戶端,同時也是同步速度最快的開源客戶端。顯然,它是更適合運行在低功耗設備上的客戶端,但它在功能更強大的服務器上也表現良好。另一方面,它的編譯和部署不像其他客戶端那樣對用戶友好。另外,Beacon節點和Validator節點在相同的可執行文件上運行的這一事實可以看作是一個特性,但也可以看作是一個缺點,因為有時在保持Beacon節點活動的同時停止Validator客戶端是很有用的。Nimbus團隊提到,他們正在開發一個獨立的Validator客戶端。
Lodestar
Lodestar是最新加入競爭的CL客戶端之一,該軟件支持其他客戶端提供的大多數功能,這確實值得稱贊。此外,它還顯示出相當低的資源消耗。然而,Lodestar并不總是易于編譯和部署(使用Docker時除外),文檔中有多個過時的說明,比如所需的nodeJS版本等。它還是從genesis同步的最慢的客戶端,而且它不提供存檔模式。
Grandine
Grandine是迄今為止同步速度最快的客戶端。它似乎有一個很棒的并行化策略,在從genesis同步時,它的性能肯定優于其他客戶端。但是,不確定這種速度在同步后會對性能產生多大的影響。還有許多功能仍處于測試階段。顯然,這個客戶端最大的缺點是它還沒有開源。
結論
在本文中,我們展示了在不同條件下進行測試時所有以太坊CL客戶端的多個方面。我們展示了他們的優點,并討論了一些需要改進的地方。在所有這些實驗之后,很明顯,不同的CL客戶端團隊專注于不同的方面、用戶和用例,他們在不同的方面表現出色。
也許應該強調的最重要的結論是,所有以太坊2 .0 CL客戶端都能在不同的硬件平臺和配置上運行良好。它們展示了以太坊強大的軟件多樣性,這在區塊鏈生態系統的其他地方是很難找到的。總的來說,我們的評估表明,所有CL客戶端實施團隊和相關研究人員的努力推動了以太坊生態系統向更可持續和可擴展的區塊鏈技術的邁進。